DUT
`timescale 1ns / 1ps
module sram_16x8(addr, clk, din, dout, we);
parameter addr_width=4, word_depth=16, word_width=8;
input [addr_width-1:0] addr;
input [word_width-1:0] din;
input clk, we;
output [word_width-1:0] dout;
reg [word_width-1:0] mem [0:word_depth-1];
reg [word_width-1:0] dout;
always@(posedge clk) begin
if(!we)
mem[addr] <= din[word_width-1:0];
end
always@(posedge clk) begin
#1 dout <= mem[addr];
end
endmoduleTB
`timescale 1ns / 1ps
module tb_sram_16x8();
parameter addr_width=4, word_depth=16, word_width=8;
reg [addr_width-1:0] addr;
reg [word_width-1:0] din;
reg clk;
reg we;
wire [word_width-1:0] dout;
sram_16x8 sram_16x8(addr, clk, din, dout, we);
always #5 clk=~clk;
initial begin
din=8'b00000000; addr=4'b0000; clk=0; we=0; #10 //write
din=8'b00000001; addr=4'b0001; #10
din=8'b00000010; addr=4'b0010; #10
din=8'b00000011; addr=4'b0011; #10
din=8'b00000100; addr=4'b0100; #10
din=8'b00000101; addr=4'b0101; #10
din=8'b00000110; addr=4'b0110; #10
din=8'b00000111; addr=4'b0111; #10
din=8'b00001000; addr=4'b1000; #10
din=8'b00001001; addr=4'b1001; #10
din=8'b00001010; addr=4'b1010; #10
din=8'b00001011; addr=4'b1011; #10
din=8'b00001100; addr=4'b1100; #10
din=8'b00001101; addr=4'b1101; #10
din=8'b00001110; addr=4'b1110; #10
din=8'b00001111; addr=4'b1111; #10
din=8'b00000000; addr=4'b0000; we=1; #10 //read
addr=4'b0001; #10
addr=4'b0010; #10
addr=4'b0011; #10
addr=4'b0100; #10
addr=4'b0101; #10
addr=4'b0110; #10
addr=4'b0111; #10
addr=4'b1000; #10
addr=4'b1001; #10
addr=4'b1010; #10
addr=4'b1011; #10
addr=4'b1100; #10
addr=4'b1101; #10
addr=4'b1110; #10
addr=4'b1111; #10
$finish;
end
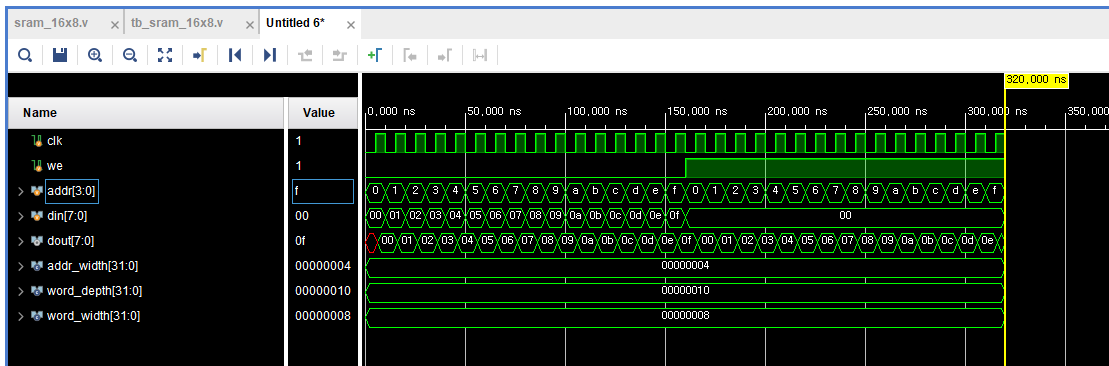
endmoduleWaveform
'Engineering(SoC Design) > (-)RAM' 카테고리의 다른 글
| Sequential vs Pipeline (0) | 2022.04.17 |
|---|---|
| SRAM vs DRAM (0) | 2022.04.17 |
| the fastest commercial sram (0) | 2022.03.19 |
| 캐시메모리 그리고 속도 (0) | 2022.03.19 |
| CPU/Memory 벤치마크 (0) | 2022.03.19 |